а) Дерево Д построенное
Рисунок 9. 8. (а) Дерево Д, построенное как результат достижения целей: внутри( 5, Д), внутри( 3, Д), внутри( 8, Д). (b) Дерево, полученное при другом порядке целей: внутри( 5, Д), внутри( 3, Д), внутри( 8, Д).
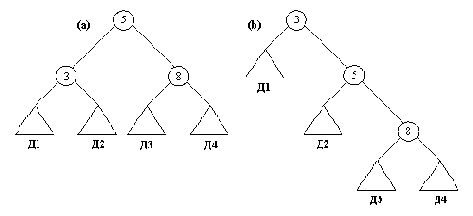
Здесь уместно сделать несколько замечаний относительно эффективности поиска в справочниках. Вообще говоря, поиск элемента в справочнике эффективнее, чем поиск в списке. Но насколько? Пусть n - число элементов множества. Если множество представлено списком, то ожидаемое время поиска будет пропорционально его длине n. В среднем нам придется просмотреть примерно половину списка. Если множество представлено двоичным деревом, то время поиска будет пропорционально глубине дерева. Глубина дерева - это длина самого длинного пути между корнем и листом дерева. Однако следует помнить, что глубина дерева зависит от его формы.
Мы говорим, что дерево (приближенно) сбалансировано, если для каждой вершины дерева соответствующие два поддерева содержат примерно равное число элементов. Если дерево хорошо сбалансировано, то его глубина пропорциональна log n. В этом случае мы говорим, что дерево имеет логарифмическую сложность. Сбалансированный справочник лучше списка настолько же, насколько log n меньше n. К сожалению, это верно только для приближенно сбалансированного дерева. Если происходит разбалансировка дерева, то производительность падает. В случае полностью разбалансированных деревьев, дерево фактически превращается в список. Глубина дерева в этом случае равна n, а производительность поиска оказывается столь же низкой, как и в случае списка. В связи с этим мы всегда заинтересованы в том, чтобы справочники были сбалансированы. Методы достижения этой цели мы обсудим в гл. 10.